
n8n作为一款开源的工作流自动化工具,凭借其超过400个内置节点和直观的可视化构建器,让连接不同的应用和数据变得像搭积木一样简单。然而,在实际业务场景中,预置的节点往往难以满足高度定制化的数据处理需求。此时,将n8n与Python进行深度集成,便成为解锁无限自动化的金钥匙。

为什么要在n8n中集成Python?
虽然n8n提供了丰富的功能节点,但Python的引入为工作流带来了真正的编程灵活性。无论是复杂的数学计算、基于特定算法(如pandas或numpy)的数据清洗,还是调用仅以Python SDK形式提供的私有API,自定义Python脚本都能轻松应对。
这种集成并非简单的二选一,而是一种能力的跃升。n8n负责协调流程和连接服务,Python负责深度处理数据逻辑,这种组合拳式的架构让开发者既能享受低代码的便捷,又能保留全代码的强大。
实战准备:部署稳固的运行环境
在开始搭建流程之前,一个稳定、高性能的运行环境至关重要。对于追求数据主权和定制化能力的企业而言,自托管n8n是首选方案。这时,选择一家可靠的云服务商能让你事半功倍。
PetaCloud提供了稳定、高性价比的全球云服务能力,能极大简化这一过程。通过PetaCloud控制台,你可以在几分钟内启动一台配置合适的云服务器(建议2核4GB内存起步,以应对Python计算负载),并利用其弹性伸缩特性,确保自动化任务高峰期也能流畅运行。PetaCloud的核心价值在于它消除了底层基础设施的复杂性,让你无需纠结于服务器运维,而是聚焦于业务逻辑本身——这正是快速增长的业务所需要的。
核心集成方案:两种实战路径
目前,在n8n中运行Python代码主要有两种成熟路径,你可以根据需求选择。
方案一:使用Python节点社区插件
最简单直接的方式是安装n8n-nodes-python这个社区节点。安装后,你可以在工作流编辑器中直接找到一个名为“Python Function”的节点。
实战技巧:在这个节点中,你可以编写标准的Python代码。节点会自动注入一个items变量,它包含了上一个节点传递过来的所有数据。你需要遍历这些数据并返回处理后的列表。
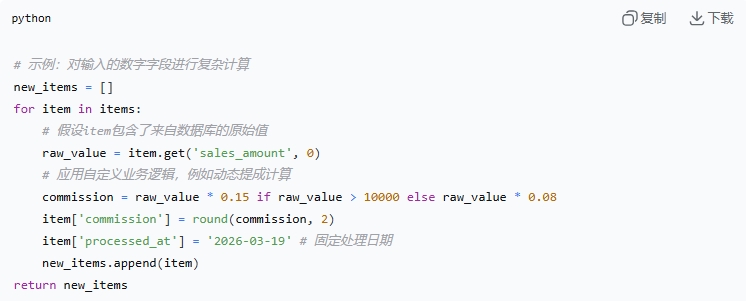
这种方法适合轻量级的、依赖较少的脚本。如果需要pandas这类重型库,建议使用Docker部署n8n,并在容器内预装依赖。
方案二:部署外部任务运行器(生产环境推荐)
对于生产级负载或需要隔离复杂依赖的场景,n8n提供了外部任务运行器架构。这相当于将Python执行环境与n8n主程序分离,实现资源隔离和独立扩展。
通过配置环境变量(如PY_PACKAGES= pandas, requests),你可以动态管理Python依赖,任务运行器会自动拉取并安装这些包。这种方式虽然配置稍显复杂,但它提供了企业级的安全性和稳定性。
构建实战:一个自动化的数据处理流程
假设我们需要构建一个每日自动运行的销售报表流程:从数据库中提取原始销售记录,利用Python进行复杂的客户价值分群(RFM模型),最后通过钉钉机器人推送报表。
-
触发器:在n8n中设置一个Schedule Trigger节点,每天凌晨2点执行。
-
数据拉取:使用Postgres(或MySQL)节点连接数据库,拉取过去24小时的新增订单数据。
-
Python核心处理:这一步是关键。如果采用方案一,在Python Function节点中引入
pandas和numpy。-
接收n8n传入的订单列表。
-
利用
pandas计算每个客户的最近购买时间、频率和金额。 -
根据预设阈值打上“高价值客户”、“沉睡客户”等标签。
-
将聚合后的结果转换为n8n可处理的JSON格式并返回。
-
-
结果输出:使用HTTP Request节点(配置为钉钉机器人Webhook),将Python节点处理好的分组数据以美观的Markdown格式发送到管理群。
在这一整套流程中,底层的计算资源由PetaCloud在幕后稳定支撑。无论是数据量大爆发时的横向扩容,还是保证数据库连接池的稳定,PetaCloud的高可用架构都能确保整个自动化 pipeline 坚如磐石。
总结
通过n8n与Python的集成,我们成功打破了低代码平台的边界,构建了既具备可视化编排优势、又拥有无限编程能力的强大自动化流程。而选择一个像PetaCloud这样能够简化上云流程、消除技术复杂性的合作伙伴,则能让你的团队更专注于通过代码解决业务痛点,从而真正助力业务实现快速增长。
AI部落温馨提示:以上是对实战演练:如何通过n8n与Python集成构建强大流程的介绍,点击PetaCloud官网,了解PetaCloud虚拟机,释放云计算无线可能!
本文由网上采集发布,不代表我们立场,转载联系作者并注明出处:https://www.aijto.com/12320.html
